
In machine learning, the data is one of the most important things while training and building intelligent models. The quality and quantity of the data affect the performance and the quality of the model. There should be a great match between the algorithm and the data in order to achieve a higher-performing and more reliable model.
There are several studies that have been conducted showing the effect of different algorithms with different datasets on the models with tracking the test accuracy of the same. These research results are used to analyze the data algorithm relationships.
In this article, we will discuss about the data, its types, the data-algorithm relationship, what makes a perfect model, the unreasonable effectiveness of the data, and finally, the significance of the data and algorithm on the final model and which is stronger.
This article will help one to understand the unreasonable effectiveness of the data phenomenon and will help one to answer the interview questions related to the same very easily and effectively.
So, before directly jumping into the core concepts, let us discuss the data and how it affects the model. Let us start with the data and its types.
What is Data?
In machine learning, the data refers to the information which is used to train, build and evaluate the intelligent model, which is used for further tasks. Sometimes it is also referred to as a dataset or data observation.
The data comes in various forms, which can be numerical, text, images, videos, audio, etc. Almost every type of data can be used to train a machine-learning model.
There are mainly two types of data:
- Structured Data
- Unstructured Data
1. Structured Data
Structured data, as the name suggests, is a type of data that is structured and can be used and analyzed very easily in a structured format. The features and the observations in the structured data are organized in the proper format, which is easy to read and access.
Examples of structured data include Excel sheets, tabular datasets, SQL databases, etc.
Training and building machine learning model with structured datasets is a relatively very easy and inexpensive process, where the dataset can easily be used, analyzed, and fed to the model for training purposes.
2. Unstructured Data
As the name suggests, unstructured data is a type of data that is not organized well. Accessing and analyzing this dataset is itself a new task that is complex and tedious. This type of dataset does not have any patterns in which the information of the dataset is stored.
Examples of this data include unlabeled image datasets, unclear audio, videos with no captions, emails with no subject and titles, etc.
Building a machine learning model with such datasets is a very complex and expensive process.
Now let us discuss the data-algorithm relationship and what makes the perfect machine learning model.
Data-Algorithm Relationship – The Perfect Model

We know that in machine learning, the data and the algorithms are one of the most important factors that affect the performance of the final model that is trained. In such cases, to achieve a very high-performing model, we need a good amount of quality data with a great match of the algorithm.
Here the algorithm being used should be matched with the behavior and the type of data and vice versa. In short, the data and algorithm choice must be optimum in order to achieve a reliable model.
For example, if we have a linear dataset, then using linear regression would be a great choice than polynomial regression or a random forest as using such algorithms will increase the complexity of the model unnecessarily and will increase the cost too.
But in case we have complex patterned data and then we are using linear regression for cost-effectiveness, and less complexity is also not good. In such cases, the optimum algorithm should be selected considering the behaviors and the outcome we need from the model.
So, in short, the best match of the data and algorithm makes the perfect model that we need for the particular problem statement, and this combination is selected with the help of domain knowledge, experience, and analyzing the situation deeply.
Now let us come to our point, the unreasonable effectiveness of the data.
Unreasonable Effectiveness of the Data
In machine learning, we already know that the data is the most influential part of model training and model building. In such cases, a small change in the quality or the quantity of the data affects a lot to the model and its performance.
In 2001, two data scientists conducted research on an NLP task where the task was to transform a text into another language. Here they were working with textual data, and we know that at that time, in late back 2001, It was very hard to collect good-quality data and train a model.
Still, they collected the data anyhow and started experimenting with different types of algorithms in data science with different sizes of training data and calculated the test data error for each case. The results they got are illustrated in the graph below.
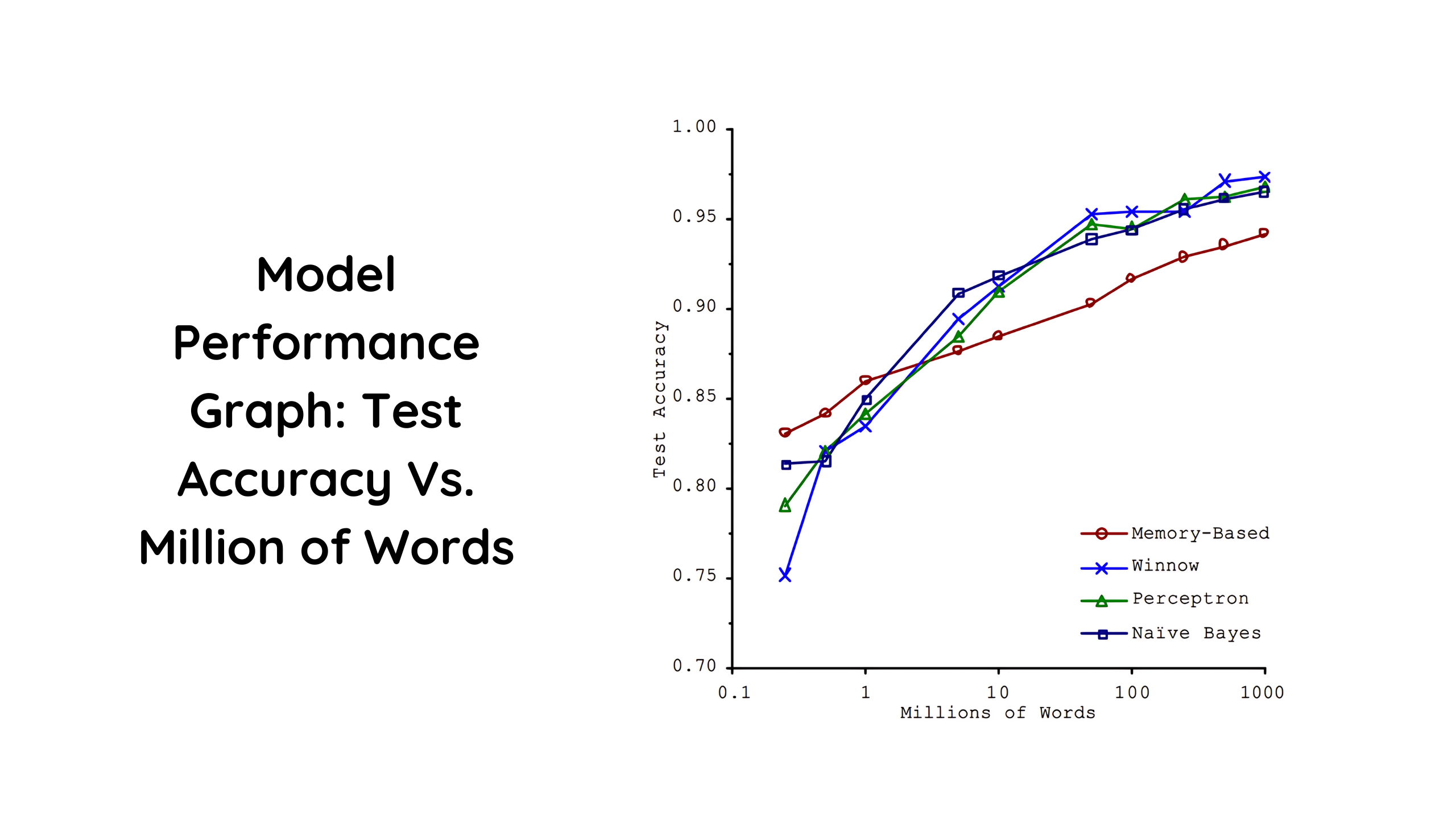
Here in the above graph, we can see that the results of the experiments with the size of the data on the x-axis and the test data accuracy on the y-axis are plotted for different algorithms like memory base algorithms, perceptrons, and traditional machine learning algorithms.
From the graph, we can clearly see at the initial stage, where the training is less, the performance, in this case, the test accuracy of the model varies, so each and every algorithm performs differently. This is because of the backend logic of the algorithm, as all of the algorithms can not have the same logic to deal with smaller kinds of data, and hence all perform very differently.
But we can see in the graph when we increase the amount of the training data and when the training data size is at peak, all of the algorithms perform almost similarly with almost the same test accuracy, which is because as we feed more and more data to the model, the model learns from the same and at a time the model learns almost all the patterns of the data and becomes stable at a single test accuracy.
We can clearly observe that in the initial stages of the algorithm, the quality matters while building a model where every algorithm performs differently according to the quality of the data, and in the last stages of the training, the quantity matters where almost all the algorithms performed similarly with high amount of data fed.
So, in short, the quality and quantity of the data affect the model most, as well as the algorithm. In the initial training stages of the model, almost all of the model with different algorithms perform differently and gives different test accuracy, whereas as the training stages pass and the model gets more data to train on, the accuracy of almost all the models with different algorithms becomes stables and same.
This concluded that every algorithm has different backend logic to deal with and hence performs differently with a smaller dataset, but as soon as we feed more data to the model, the model learns from the same, and almost every algorithm can learn all the patterns of the data and finally gives the same accuracy, this phenomenon is called unreasonable effectiveness of the data.
Now we may have a gentle question after knowing this phenomenon, if we are getting almost the same accuracy with larger datasets in all the algorithms, then what is the need to develop advanced algorithms? Why not collect great quality and quantity data and then train models with the same with simpler algorithms?
However, this question was also raised when this research took place, and in response to this, it was concluded that the algorithm also has its own impact on the final models, and hence the best-fit combination of the data and algorithm should be selected instead giving the importance only to the data.
Now let us discuss that why every model performs differently at the initial and last stages.
Why do Models Perform Differently at the Initial Stages?
We can see in the graph above that almost all the models have different test accuracy in the initial stages of the training. This is because the algorithms which are used to train the models are different for each.
Here we can see that at the initial stages, the memory-based models perform well; this is because the nature of the memory-based algorithms is to memorize the data and then use it to predict for the future. However, in the final stages of the training, these models fail as it is very hard to memorize such large datasets.
On the other hand, the perceptron and winnow models perform poorly at the initial stages because they are most likely to be the deep learning algorithms, and they do need more data to train on and result in an accurate model.
Let us discuss the significance of the data and algorithm on the models.
Which is More Significant: The Data or The Algorithm?
As we saw in the graph of the size of the data vs. the test accuracy of the model for different algorithms, we can clearly understand that a high amount of the data can change the performance of almost any kind of model trained with even lower quality algorithms that are not best suited for the problem statement.
Till then, it was assumed that the algorithm was the only thing that should be focused on, and the algorithm should be good in order to achieve a reliable model, but this experiment back in 2011 showed that if the quality and quantity of the data are good, then almost we can have a reliable model with lower performing algorithm.
So here is a direct answer to the question, “Why develop complex algorithms?” is a trade-off; the data and the algorithm have trade-offs while training and building a model. Hence both should be of good fit, and both should have strong communication and significance in the model.
In general, with only the higher quality and quantity of data, we can choose a good model, but every time the quality and quantity of the data cannot be good, and every problem statement cannot have a sufficient amount of data in the market, or it can not be generated as well. On the other hand, the same thing is true for the algorithms.
This can also be observed in the graph, as at the initial stages of the training, every algorithm performs differently with the same type of data fed with the same quality and quantity, where every algorithm has different logic to deal with lower quality and quantity of the data. Hence the algorithms also play major roles and should b selected wisely.
So it is always better that we keep both the algorithm and the data in mind while building and training a machine learning model, and we should try to have a better algorithm that best suits the problem statement as well as the high quality and quantity of the data.
Key Takeaways
1. The quality and quantity of the data are things that influence the performance of the model in almost all ways.
2. In 2001, according to the research of two data scientists, it was proved that a high amount of data could also give a reliable model with a lower-performing algorithm.
3. The data and the algorithm in machine learning have trade-offs, and both should be optimum while selecting and working on the same.
4. According to the results obtained back in 2001, the quality of the data and the algorithm matters when there is less quantity of the data, where the higher performing model can be achieved with the same.
5. However, as more and more data is fed to the model, the effect of the algorithm on the performance of the model disappears, and every model with a different algorithm performs almost similarly.
6. To achieve the best performing and reliable model in machine learning, the primary focus would be to have a good amount of data with good quality as well as the best-suited algorithm for the data and the problem statement.
Conclusion
In this article, we discussed the unreasonable effectiveness of the data, what data is, what its types are, what is a data-algorithm relationship, what is needed to achieve a perfect model, and finally, what our focus should be to achieve a higher performing model.
This article concludes that both data and algorithm have a good effect on the final model and should be selected with a good match and optimistically. They have their own significance and should be considered and leveraged while building and implementing the machine learning model.
This article will help one to understand the inreasonall effectiveness of data phenomenon and will help answer interview questions related to ther same very easily and efficienmtly.
